搜索引擎使用
常见的搜索引擎我们使用fofa、hunter(奇安信的全球鹰)、灯塔、google
序号 | 语法 | 语法说明 | 示例 | 示例说明 |
|---|
1 | + | 同AND,搜索包含多个关键词的结果 | 搜索 + 引擎 | 搜索包含【搜索】和【引擎】两个词的页面 |
2 | OR | 或者 | 搜索 OR 引擎 | 搜索包含【搜索】或【引擎】两个词的页面 |
3 | – | 减号,不包含减号后面词的页面 | 搜索引擎 -百度 | 搜索不包括【百度】的【搜索引擎】的页面 |
4 | “” | 双引号,精确匹配 | “搜索引擎” | 精确匹配【搜索引擎】这个关键词的页面 |
5 | * | 星号,通配符,模糊搜索,星号代替某个字 | 搜*引擎 | 星号可以为任何字 |
6 | @ | 在用于搜索社交媒体的字词前加上@ | trump @twitter | 搜索trump的twitter |
7 | $ | 在数字前加上$搜索特定价格 | camera $400 | 搜索400$的camera |
8 | # | 搜索 # 标签 | #throwbackthursday | 搜索标签throwbackthursday |
9 | .. | 两个点,在两个数字之间加上.. 在数字范围内执行搜索 | camera 500..1000 | 搜索500−1000的camera |
10 | filetype | 搜索某一种文件类型的资源 | C++ filetype:pdf | 搜索类型为pdf的C++网页资源 |
11 | site | 在指定站点搜索 | C++ site:https://www.zhihu.com | 在知乎中搜索和C++相关的网页 |
12 | cache | 查看网站的 Google 缓存版本,会直接显示缓存页面 | cache:weibo.com | 查看微博的谷歌快照 |
13 | info | 在网址前加info:,获取网站详情 | info:github.com | 搜索github网站详情 |
14 | related | 搜索与某个网站有关联的页面 | related:sina.com | 和新浪网网站结构内容相似的一些其它网站 |
15 | link | 返回所有链接到某个URL地址的网页 | link:www.csdn.net | 搜索所有含指向【www.csdn.net】链接的网页 |
16 | inurl | 搜索查询词出现在url 中的页面 | inurl:搜索引擎 | 搜索链接url中有【搜索引擎】的网页 |
17 | intitle | 搜索查询词出现在页面标题(title)中的页面,支持中文和英文 | intitle:搜索引擎 | 搜索页面标题中有【搜索引擎】的网页 |
18 | intext | 搜索查询词出现在页面正文(title)中的页面,支持中文和英文 | SEO intext:搜索引擎 | 在正文包含【搜索引擎】的网页中搜索【SEO】 |
19 | inanchor | 搜索链接锚文字(即链接显示的文字)中包含搜索词的页面 | inanchor:前端 | 搜索链接锚文字中包含【前端】的页面 |
20 | allinurl | 即all+inurl 页面url中包含多个关键词的页面 | allinurl:SEO 搜索引擎优化 | 相当于 :inurl:SEO inurl:搜索引擎优化 |
21 | allintitle | 即all+intitle 页面标题中包含多个关键词的页面 | allintitle:SEO 搜索引擎优化 | 相当于:intitle:SEO intitle:搜索引擎优化 |
22 | allintext | 即all+inanchor 页面正文包含多个关键词的页面 | allintext:SEO 搜索引擎优化 | 相当于:intext:SEO intext:搜索引擎优化 |
23 | allinanchor | 即all+inanchor 页面链接锚文字包含多个关键词的页面 | allinanchor:SEO 搜索引擎优化 | 相当于:inanchor:SEO inanchor:搜索引擎优化 |
24 | weather | weather/time/sunrise/sundown+城市名,返回城市的天气/时间/日出时间/日落时间 | weather:beijing | 显示北京的天气 |
25 | music | 或者用songs,歌手名字+music/songs | 周杰伦 music | 返回周杰伦的各首歌曲 |
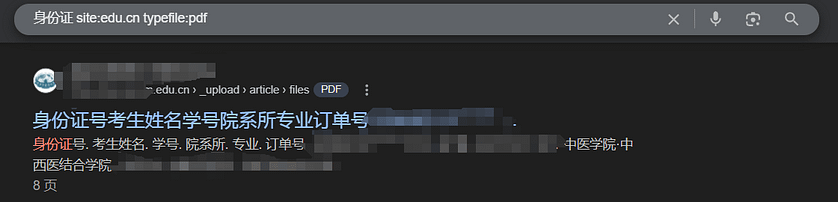
比如我们使用上面语法,可以搜索到以edu.cn结尾的网站,使用typefile字段可以搜索到以xxx后缀结尾的文件,前面直接加上要搜索的内容,整一条就可以搜索到包含身份证的来自某学校官网的泄露的身份证信息的pdf,当然一般搜索出来的这类敏感信息都有打码,我们甚至可以搜索学号等信息
fofa网址:FOFA
site:指定域名,如:site:edu.cn
inurl:用于搜索包含的url关键词的网页,如:inurl:id=23 搜索网址中id为23的网页
intitle:搜索网页标题中的关键字,如:intitle:index
intext:搜索网页正文中的关键字,如:intext:登陆/注册/用户名/密码
filetype:按指定文件类型即文件后缀名搜索,如filetype:php/asp/jsp
cache:已经删除的缓存网页,推荐组合使用
link:搜索所有链接到某个特定url的页面
info:查看指定站点的基本信息
举一个例子:比如想挖edu该如何做信息收集呢?
"系统" && org="China Education and Research Network Center" && status_code="200" && country="CN" && host="edu.cn"
如上:指定我们搜索的是系统业务,org指的是组织:China Education and Research Network Center指的就是教育组织,status_code指的是业务状态200就是正常,country是所处国家,host是说网站以什么结尾,我这里指的就是所有xxxx.edu.cn的网站
部分特殊fofa语法参考:https://github.com/Sweelg/Fofa-grammar
Hunter(鹰图平台)
网址:Hunter(鹰图平台)
ip.tag=”CDN” hot特色 | 查询包含IP标签”CDN”的资产
(查看枚举值) |
web.similar=”baidu.com:443″ hot特色 | 查询与baidu.com:443网站的特征相似的资产 |
web.similar_icon==”17262739310191283300″ hot特色 | 查询网站icon与该icon相似的资产 |
web.similar_id=”3322dfb483ea6fd250b29de488969b35″ hot特色 | 查询与该网页相似的资产 |
web.tag=”登录页面” hot特色 | 查询包含资产标签”登录页面”的资产
(查看枚举值) |
domain.suffix=”qianxin.com” hot | 搜索主域为”qianxin.com”的网站 |
web.icon=”22eeab765346f14faf564a4709f98548″ hot | 查询网站icon与该icon相同的资产 |
ip.port_count>”2″ hot | 搜索开放端口大于2的IP(支持等于、大于、小于) |
is_web=true hot | 搜索web资产 |
cert.is_trust=true hot | 搜索证书可信的资产 |
icp.province=”江苏” new | 搜索icp备案企业注册地址在江苏省的资产 |
icp.city=”上海” new | 搜索icp备案企业注册地址在“上海”这个城市的资产 |
icp.district=”杨浦” new | 搜索icp备案企业注册地址在“杨浦”这个区县的资产 |
web.similar=”baidu.com:443″ hot特色 | 通过网络特征搜索资产 |
web.similar_id=”3322dfb483ea6fd250b29de488969b35″ hot特色 | 搜索相似网站 |
web.similar_icon==”17262739310191283300″ hot特色 | 搜索相似网站icon搜索资产 |
web.tag=”登录页面” hot特色 | 搜索网站标签搜索资产
(查看枚举值) |
ip.tag=”CDN” hot特色 | 搜索IP标签搜索资产
(查看枚举值) |
icp.is_exception=true 特色 | 搜索含有ICP备案异常的资产 |
ip=”1.1.1.1″ | 搜索IP为 ”1.1.1.1”的资产 |
ip=”220.181.111.0/24″ | 搜索网段为”220.181.111.0″的C段资产 |
ip.port=”80″ | 搜索开放端口为”80“的资产 |
ip.country=”中国” 或 ip.country=”CN” | 搜索IP对应主机所在国为”中国“的资产 |
ip.province=”江苏” | 搜索IP对应主机在江苏省的资产 |
ip.city=”北京” | 搜索IP对应主机所在城市为”北京“市的资产 |
ip.isp=”电信” | 搜索运营商为”中国电信”的资产 |
ip.os=”Windows” | 搜索操作系统标记为”Windows“的资产 |
app=”Hikvision 海康威视 Firmware 5.0+” && ip.ports=”8000″ | 检索使用了Hikvision且ip开放8000端口的资产 |
ip.port_count>”2″ hot | 搜索开放端口大于2的IP(支持等于、大于、小于) |
ip.ports=”80″ && ip.ports=”443″ | 查询开放了80和443端口号的资产 |
ip.tag=”CDN” hot特色 | 查询包含IP标签”CDN”的资产
(查看枚举值) |
domain.status=”clientDeleteProhibited” | 搜索域名状态为”client Delete Prohibited”的网站
(查看枚举值) |
domain.whois_server=”whois.markmonitor.com” | 搜索whois服务器为”whois.markmonitor.com”的网站 |
domain.name_server=”ns1.qq.com” | 搜索名称服务器为”ns1.qq.com”的网站 |
domain.created_date=”2022-06-01″ | 搜索域名创建时间为”2022-06-01″的网站 |
domain.expires_date=”2022-06-01″ | 搜索域名到期时间为”2022-06-01″的网站 |
domain.updated_date=”2022-06-01″ | 搜索域名更新时间为”2022-06-01″的网站 |
domain.cname=”a6c56dbcc1f22283.qaxanyu.com” | 搜索cname包含“a6c56dbcc1f22283.qaxanyu.com”的网站 |
is_domain.cname=true | 搜索含有cname解析记录的网站 |
不一一列举了,是从官网上扒下来的,查询语法直接看官网就行,除了以上常用的之外其他的搜索引擎参考网络空间资产测绘网站
子域名挖掘思路
子域名是什么东西?子域名能够起到什么作用?
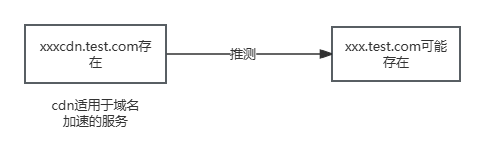
(1)猜域名
分析js代码中可能可以发现xxxcdn.test.com等陌生域名,cdn一般表示静态文件存放的域名,那么xxx.test.com就可能存在。

在js中可能产生很多泄露,虽然可能看不懂但是可能会导致很多东西泄露
(2)猜接口
首先我们要知道在SRC中修改和删除不一定是高危,可能也就是中危,但是在SRC中查询信息泄露大概率会有高危,通过猜测某个js里面没有的接口(也就是前端没有但是后端有),可能导致未授权访问
原接口(可以做到修改用户信息)
POST /api/modify_bank_account
猜测接口(可以查询信息导致信息泄露)
POST /api/query_bank_account
(3) 403 bypass
怎么去理解呢?
POST /api/platform/permission/team
# 当我们访问这个接口时会显示无权访问,联系管理员
POST /api/platform/1/../permission/team
# 当我们再访问这个类似这个接口时会显示正常信息
原理:产生这个漏洞说明是前后端分离的服务器
后端的第一层服务器一般都是中间件负责负载和鉴权,后端第一层服务器(这里简称为前端)鉴权的时候可能不处理../,那就导致对于前端来说就相当于/api/platform/1/../permission/team这个接口是没有的,没有这个接口不会走到鉴权函数和if语句里面去 , 但是在后端第二层服务器又会负责处理数据返回数据包处理这个../,就会导致本来不存在的接口被后端服务器处理之后变成了/api/platform/permission/team这个存在的接口,然后前端服务器对外来数据包鉴权但是可能不会对后端服务器发送的数据包鉴权就导致403bypass掉了,于此就成功提权,漏洞是前后端处理不一致。
POST /api/platform/permission/team
# 当我们访问这个接口时会显示无权访问,联系管理员
POST /api/platform/permission/team.json
# 当我们再访问这个类似这个接口时会显示正常信息
还是一样的问题,就是前端可能对/api/platform/permission/team.json这个路径请求不到,所以认为没有这个接口,但是到后端时,有可能后端会自动忽略.json 这就导致接口被后端再次解析请求发回前端导致403bypass
(4)测试版本、国内版本
为什么要测试测试版本、国内版本呢?
因为国外微信、QQ、微博等遍及率不算太高,导致外网在登陆时一般不使用QQ、微信、微博等账号
这就意味着在登陆时可能就会多了注册、账号密码登陆等功能,可以进行SQL,账号密码重置等漏洞